Chapter 8 Descriptive statistics
8.1 Measure of Centrality
## [1] 11 2 35 46 55## [1] 29.8## [1] 35## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.0 11.0 35.0 29.8 46.0 55.0## 0% 25% 50% 75% 100%
## 2 11 35 46 55## 25%
## 11## 50%
## 35## 75%
## 46## 30% 45% 65%
## 15.8 30.2 41.68.2 Measure of Spread
## [1] 512.7## [1] 22.64288## [1] 2 55## [1] 53## [1] 35# Estimate IQR by yourself, IQR= quantile3-quantil1 i.e. Q3-Q1
# Compare the result with the result of IQR function
q1 = quantile(x = data, probs = 0.25); # First quantile
q3 = quantile(x = data, probs = 0.75); # Third quantile
print(q3-q1);## 75%
## 358.3 Handle missing values
## [1] 11 2 35 46 55## [1] 11 2 35 46 55 NA## [1] NA## [1] 29.8# u have to use na.rm in median, var, sd, IQR, range, quantile function
summary(data); # no need to give na.rm, NA are treated separately## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 2.0 11.0 35.0 29.8 46.0 55.0 18.3.1 Shape / Data Distribution
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa# Check sepal length distribution
# Since sepal length is numerical data, we can use hist() and density() to see the distribution
# Histogram
hist(iris$Sepal.Length, xlab="Sepal Length", main="Histogram of Sepal Length");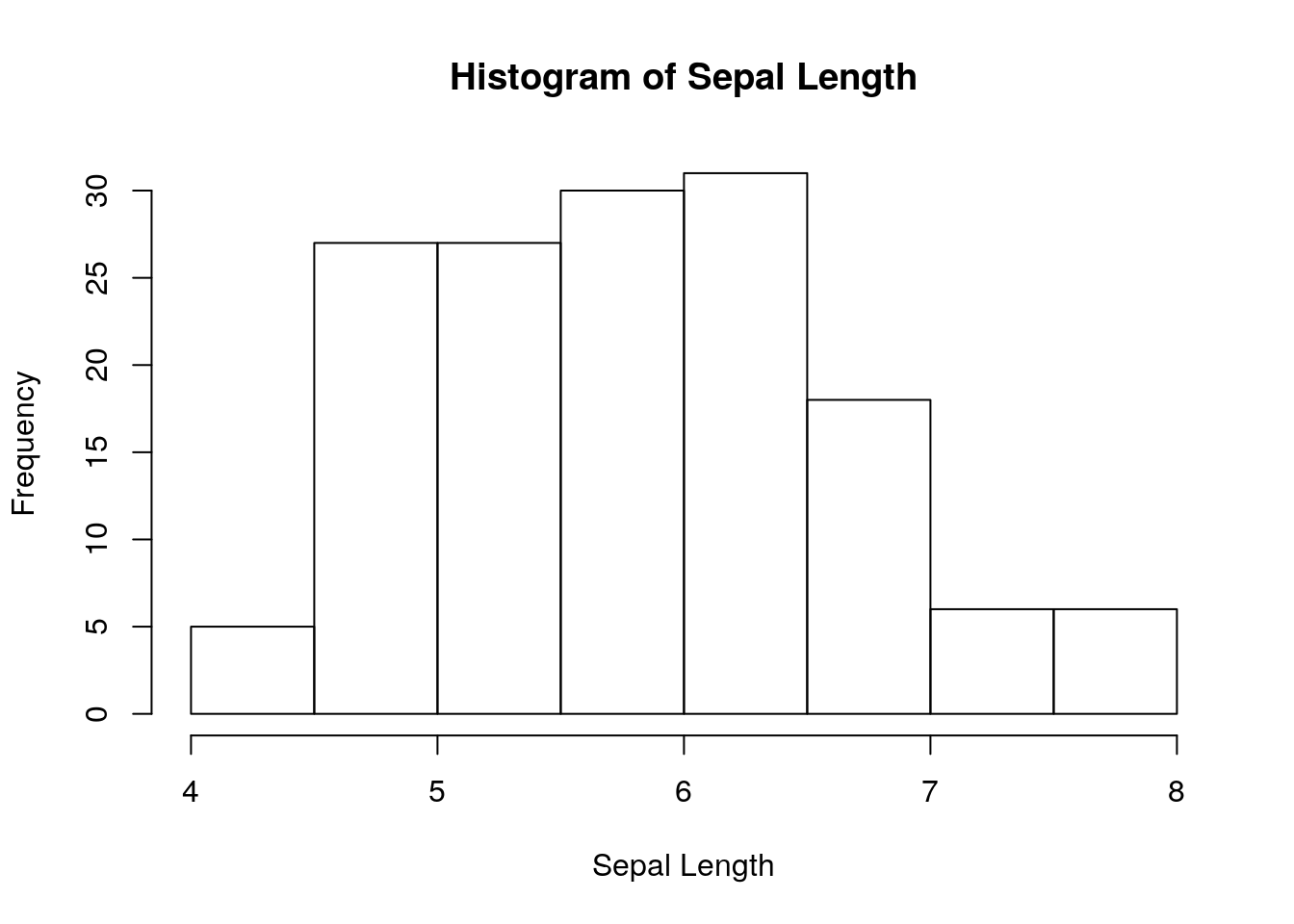
# Density plot
# You can see its a unimodal distribution
plot(density(iris$Sepal.Length), xlab="Sepal Length", main="Density of Sepal Length")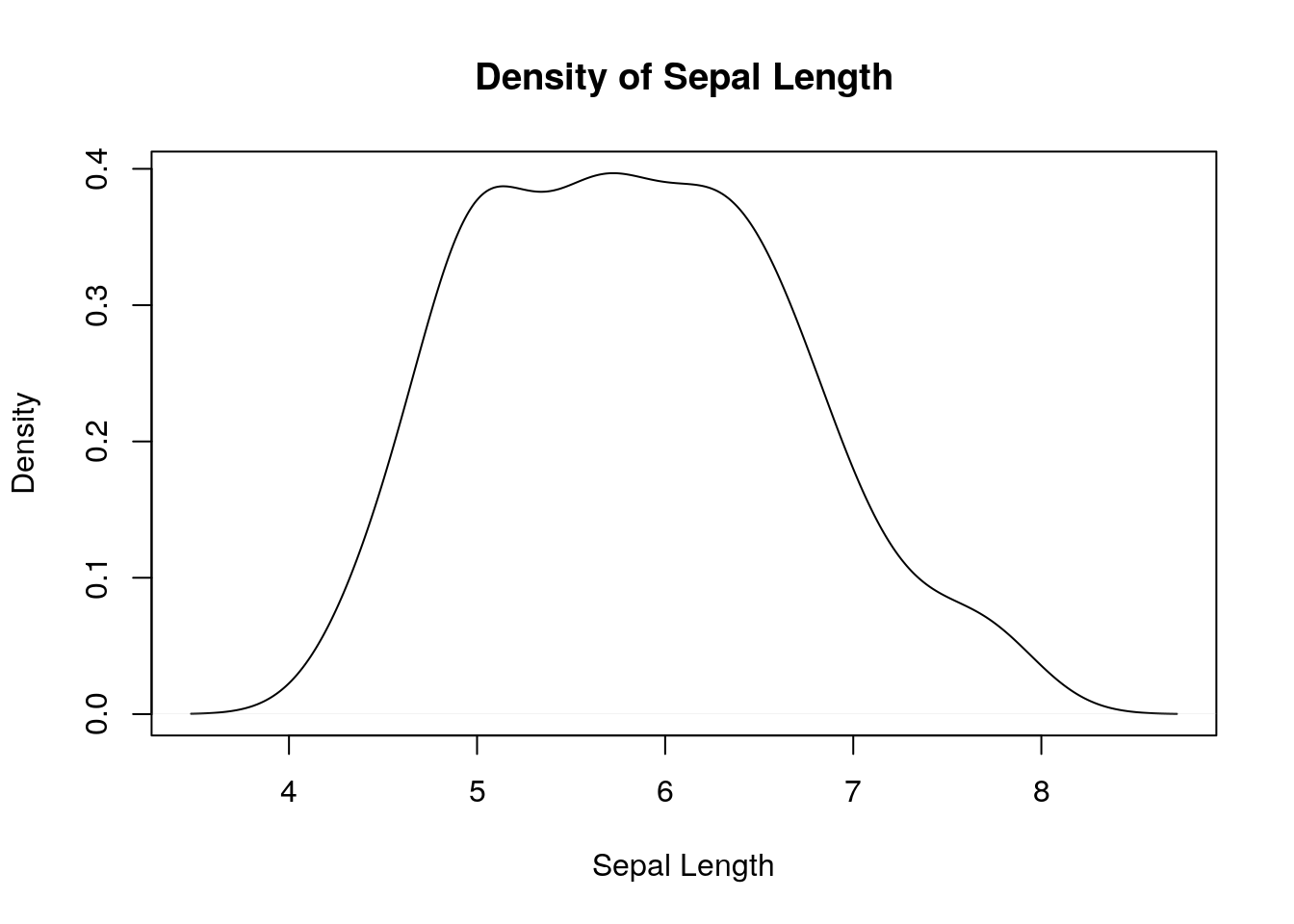
# Histogram of four features (Sepal.Length Sepal.Width Petal.Length Petal.Width) of iris dataset
par(mfrow=c(2,2));
hist(iris$Sepal.Length, xlab="Sepal Length", main="Histogram of Sepal Length")
hist(iris$Sepal.Width, xlab="Sepal Width", main="Histogram of Sepal Width")
hist(iris$Petal.Length, xlab="Petal Length", main="Histogram of Petal Length")
hist(iris$Petal.Width, xlab="Petal Width", main="Histogram of Petal Width")
# Density plot of four features (Sepal.Length Sepal.Width Petal.Length Petal.Width) of iris dataset
par(mfrow=c(2,2));
plot(density(iris$Sepal.Length), xlab="Sepal Length", main="Density plot of Sepal Length")
plot(density(iris$Sepal.Width), xlab="Sepal Width", main="Density plot of Sepal Width")
plot(density(iris$Petal.Length), xlab="Petal Length", main="Density plot of Petal Length")
plot(density(iris$Petal.Width), xlab="Petal Width", main="Density plot of Petal Width")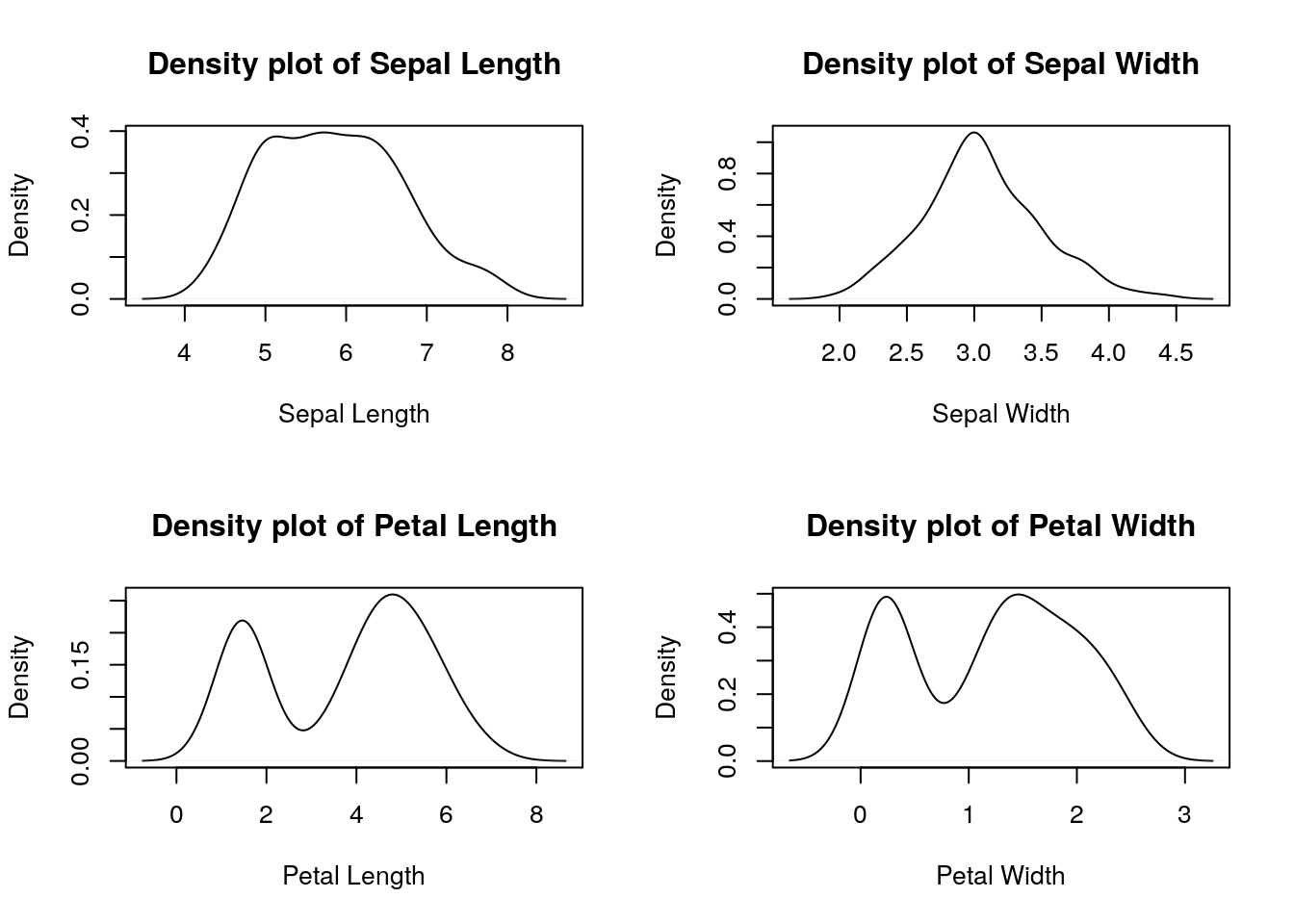
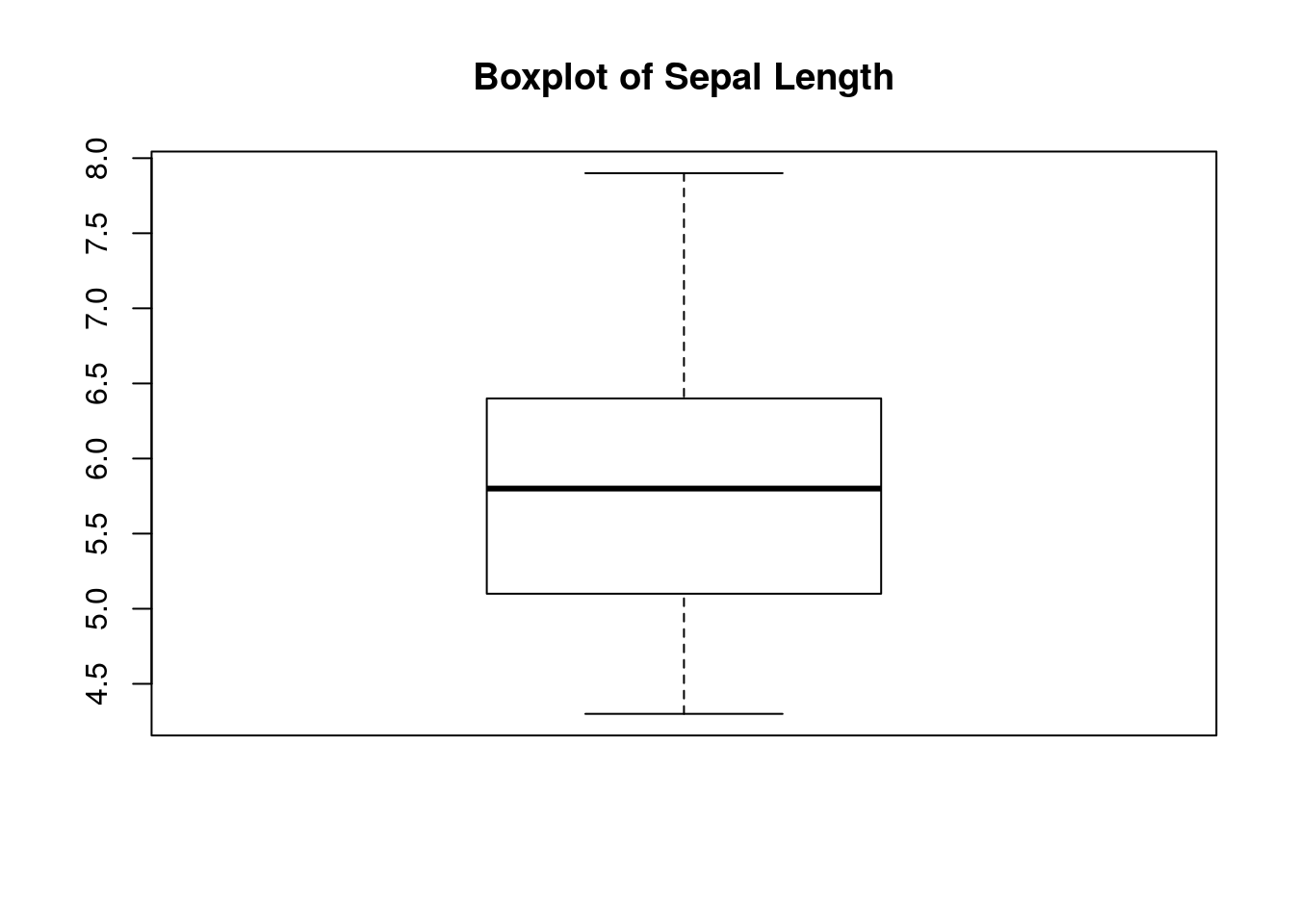
# Box plot of four features (Sepal.Length Sepal.Width Petal.Length Petal.Width) of iris dataset
par(mfrow=c(1,1));
boxplot(iris[,1:4])
# Density plot of four features (Sepal.Length Sepal.Width Petal.Length Petal.Width) of iris dataset. Mean is marked in red line while median in blue.
par(mfrow=c(2,2));
plot(density(iris$Sepal.Length), xlab="Sepal Length", main="Density plot of Sepal Length")
meanval= mean(iris$Sepal.Length)
medianval=median(iris$Sepal.Length);
lines(c(meanval, meanval),c(0,1), lwd=2, col="red"); # mean line
lines(c(medianval, medianval),c(0,1), lwd=2, col="blue"); # mean line
plot(density(iris$Sepal.Width), xlab="Sepal Width", main="Density plot of Sepal Width")
meanval= mean(iris$Sepal.Width)
medianval=median(iris$Sepal.Width);
lines(c(meanval, meanval),c(0,1), lwd=2, col="red"); # mean line
lines(c(medianval, medianval),c(0,1), lwd=2, col="blue"); # mean line
plot(density(iris$Petal.Length), xlab="Petal Length", main="Density plot of Petal Length")
meanval= mean(iris$Petal.Length)
medianval=median(iris$Petal.Length);
lines(c(meanval, meanval),c(0,1), lwd=2, col="red"); # mean line
lines(c(medianval, medianval),c(0,1), lwd=2, col="blue"); # mean line
plot(density(iris$Petal.Width), xlab="Petal Width", main="Density plot of Petal Width")
meanval= mean(iris$Petal.Width)
medianval=median(iris$Petal.Width);
lines(c(meanval, meanval),c(0,1), lwd=2, col="red"); # mean line
lines(c(medianval, medianval),c(0,1), lwd=2, col="blue"); # mean line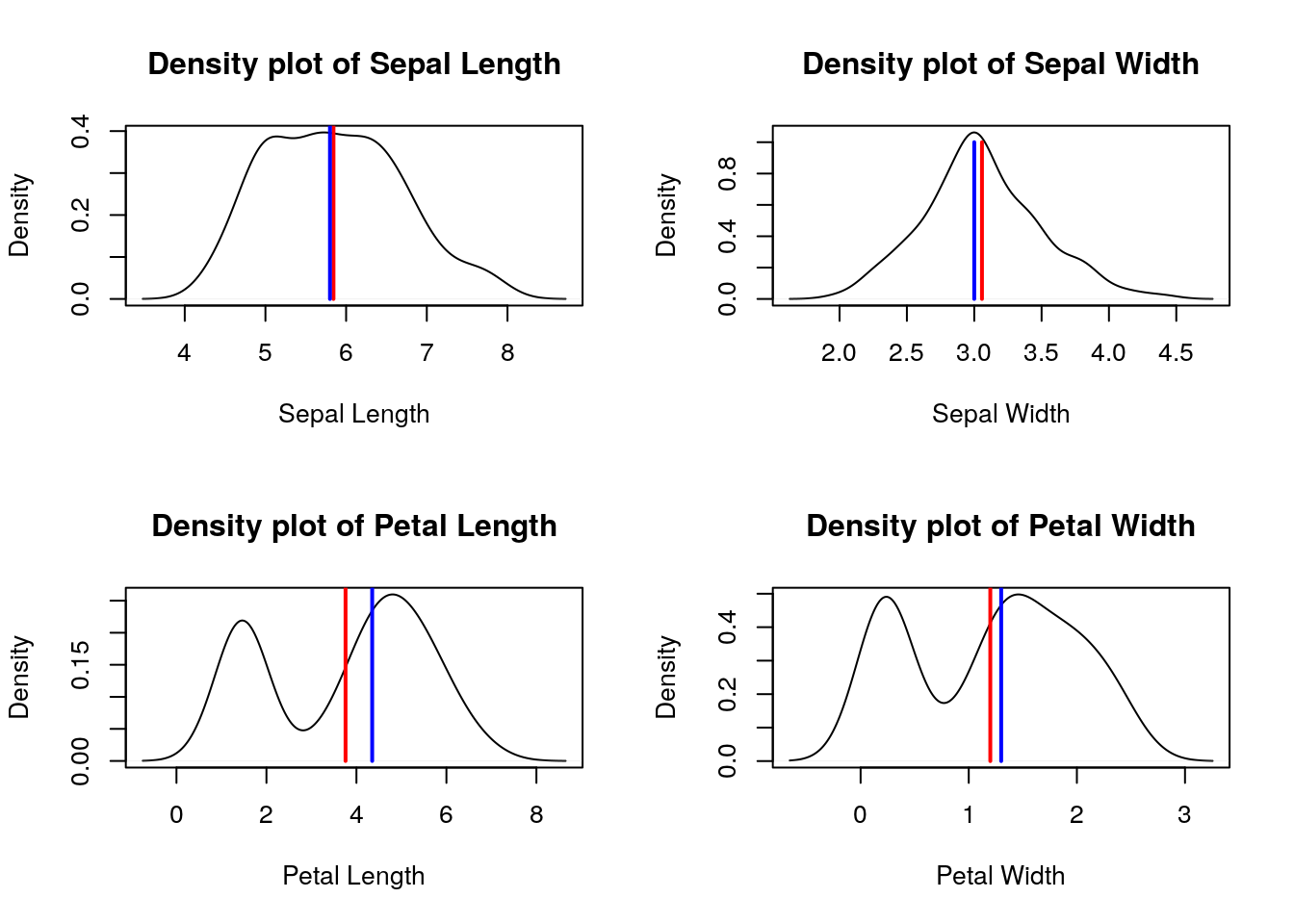
8.4 Estimate Skewness and Kurtosis
Load the moments library
Calculate skewness. Skewness is a measure of symmetry.
Negative skewness: mean of the data < median and the data distribution is left-skewed.
Positive skewness: mean of the data > median and the data distribution is right-skewed.
## [1] 0.3117531## [1] 0.3157671## [1] -0.2721277## [1] -0.1019342Estimate kurtosis. kurtosis describes the tail shape of the data distribution.
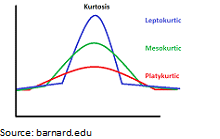
The normal distribution has zero kurtosis and thus the standard tail shape. It is said to be mesokurtic.
Negative kurtosis would indicate a thin-tailed data distribution, and is said to be platykurtic.
Positive kurtosis would indicate a fat-tailed distribution, and is said to be leptokurtic.
## [1] 2.426432## [1] 3.180976## [1] 1.604464## [1] 1.6639338.5 Further with Skewness and Kurtosis.
Source: http://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm
Many classical statistical tests and intervals depend on normality assumptions. Significant skewness and kurtosis clearly indicate that data are not normal. If a data set exhibits significant skewness or kurtosis (as indicated by a histogram or the numerical measures), what can we do about it?
One approach is to apply some type of transformation to try to make the data normal, or more nearly normal. The Box-Cox transformation is a useful technique for trying to normalize a data set. In particular, taking the log or square root of a data set is often useful for data that exhibit moderate right skewness.
Another approach is to use techniques based on distributions other than the normal. For example, in reliability studies, the exponential, Weibull, and lognormal distributions are typically used as a basis for modeling rather than using the normal distribution.